Databases and ORMs
For both C# and TypeScript, there are a number of ORMs available to help teams interface with databases more productively. ORMs typically provide features such as binding of query results to domain models, simplifying the read and write of records from and to the database, as well as handling schema migrations. Microsoft ships a first-party ORM -- Entity Framework Core (EF Core) -- which is mature and has a large number of database providers supported. However, there are third party libraries available including NHibernate (and FluentNHibernate) as well as Dapper (which is not a full ORM)
The Node.js ecosystem has a large number of NPM packages available including Prisma (14m+ downloads, ~42k stars), TypeORM (9m+ downloads, ~35k stars), Sequelize (9m+ downloads, ~30k stars), and Drizzle (4m+ downloads, ~27k stars). There are also query builder libraries like Kysely (2m+ downloads, ~12k stars) which perhaps maps more closely to a Dapper than a true ORM.
We'll compare the most popular Node.js library, Prisma, against EF Core and see where they align and where they differ. We'll also see how the usage of LINQ in EF enables much more fluid query building.
⭐️ A focus on productivity ⭐️
Pay attention to the notes and callouts here because they go in depth on how Entity Framework can significantly boost productivity for backend teams.
Start the Postgres Docker instance first
Before running the examples and unit tests, start the Postgres container instance via docker compose up.
See the docker-compose.yaml file for more details. The databases are dropped and re-created on each run.
Setting Up
Here, we'll create a simple API app using Nest.js and .NET controller web APIs along with unit tests to demonstrate how these ORMs work and how they plug into the DI system of common platform runtimes.
# Create the app in /src/typescript/prisma-api
cd src/typescript
nest new prisma-api
cd prisma-api
# Add Prisma
yarn add -D prisma
# Initialize prisma (see output below)
npx prisma init
# Next steps:
# 1. Set the DATABASE_URL in the .env file to point to your existing database. If your database has no tables yet, read https://pris.ly/d/getting-started
# 2. Set the provider of the datasource block in schema.prisma to match your database: postgresql, mysql, sqlite, sqlserver, mongodb or cockroachdb.
# 3. Run prisma db pull to turn your database schema into a Prisma schema.
# 4. Run prisma generate to generate the Prisma Client. You can then start querying your database.
# 5. Tip: Explore how you can extend the ORM with scalable connection pooling, global caching, and real-time database events. Read: https://pris.ly/cli/beyond-orm
# Install the Prisma schema extension for VS Code: https://marketplace.visualstudio.com/items?itemName=Prisma.prisma
# Add the client
yarn add @prisma/client# Create the app in /src/csharp/ef-api
cd src/csharp
mkdir ef-api
cd ef-api
dotnet new webapi --use-controllers --no-https
# Add Pg driver for Entity Framework
dotnet add package Npgsql.EntityFrameworkCore.PostgreSQL
# Add to allow snake_case naming (because Pg and caps are no fun)
dotnet add package EFCore.NamingConventions
# Add for migrations
dotnet add package Microsoft.EntityFrameworkCore.Design
# Add for unit tests
dotnet add package XUnitSource code
💡 The source code for this walkthrough is available in GitHub.
Wiring Postgres
Next, we wire our Postgres driver and connect it to our runtime.
// 📄 Update .env
DATABASE_URL="postgresql://postgres:postgres@localhost:5432/prisma-api?schema=public"
// 📄 Add to .eslintrc.js to fix linting issues for Nest in sub-folder
// See: https://github.com/microsoft/vscode-eslint/issues/1170#issuecomment-811871985
project: path.join(__dirname, "tsconfig.eslint.json"),
// 📄 prisma.service.ts (imports omitted)
@Injectable()
export class PrismaService extends PrismaClient implements OnModuleInit {
async onModuleInit() {
await this.$connect();
}
}
// 📄 app.service.ts (imports omitted)
@Injectable()
export class AppService {
constructor(
private readonly prismaService: PrismaService
) { }
// Snipped...
}
// 📄 app.module.ts (imports omitted)
@Module({
imports: [],
controllers: [AppController],
providers: [AppService, PrismaService],
})
export class AppModule {}
// 📄 tsconfig.json
{
compilerOptions: {
// Add to support auto-transaction rollback.
"types": ["@types/jest", "@quramy/jest-prisma"]
}
}// 📄 Database.cs
// This is just for us to inject the connection string (and other config)
public record DbConfig(string ConnectionString);
// This is our database. The key is to inherit from DbContext
public class Database(DbConfig config) : DbContext {
// This method gets called on startup and we'll configure our database
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder) {
if (optionsBuilder.IsConfigured){
return;
}
optionsBuilder
.UseNpgsql(config.ConnectionString, o => o.UseAdminDatabase("postgres"))
.UseSnakeCaseNamingConvention()
.EnableDetailedErrors() // ⚠️ ONLY DEV CODE
.EnableSensitiveDataLogging(); // ⚠️ ONLY DEV CODE
}
}
// 📄 Program.cs
var connectionString = "server=127.0.0.1;port=5432;database=momo;user id=postgres;password=postgres;include error detail=true;";
builder.Services.AddSingleton(new DbConfig(connectionString));
builder.Services.AddDbContext<Database>();
var app = builder.Build();
// ⚠️ ONLY DEMO CODE; NOT FOR PROD ⚠️
// Get our database from DI and ensure we create it
// (because our Docker container is ephemeral)
using var scope = app.Services.CreateScope();
var db = scope.ServiceProvider.GetService<Database>()!;
db.Database.EnsureCreated();This is just demo code!
Note that the last block of code is just demo code! You do not need to do this in normal apps. Here we are just applying the schema at startup for the purposes of this demo.
Creating a Schema
Let's see how we define a schema for each platform.
Keep an eye out for types
As you go through this series of exercises, keep an eye out for how the EF Core examples allow types to flow through the entire chain, preventing errors and mistakes at dev, build, and runtime.
At no point in these examples does EF require usage of strings to reference properties, operations, and so on.
This is because expression trees are first-class entities in C# and allow runtime evaluation of C# expressions as syntax elements.
// 📄 schema.prisma
// 🏃♀️ Runners
model Runner {
id Int @id @default(autoincrement())
name String
email String @unique
country String
races RaceResult[]
@@index([email])
@@map("runner") // Pg doesn't like upper case
}
// 🏎️ Races
model Race {
id Int @id @default(autoincrement())
name String
date DateTime
distanceKm Float
runners RaceResult[]
@@index([date])
@@map("race") // Pg doesn't like upper case
}
// 🥇 Results (maps many-to-many)
// This is an explicit table since we need access to the properties
// through the navigation of the properties
model RaceResult {
runnerId Int
raceId Int
position Int
time Int
bibNumber Int
runner Runner @relation(fields: [runnerId], references: [id])
race Race @relation(fields: [raceId], references: [id])
@@id([runnerId, raceId])
@@index([bibNumber])
@@map("race_result")
}
// 1️⃣ Run: npx prisma generate
// 2️⃣ Run: npx prisma migrate reset
// 3️⃣ Run: npx prisma migrate dev --name initpublic class Database(DbConfig config) : DbContext {
// 👇 These two define our schema
public DbSet<Runner> Runners { get; set; } = null!;
public DbSet<Race> Races { get; set; } = null!;
// Snipped...
}
// 🏃♀️ Runners
[Index(nameof(Email))]
public class Runner {
[DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int Id { get; set; }
public required string Name { get; set; }
public required string Email { get; set; }
public required string Country { get; set; }
[JsonIgnore] // 👇 Do not serialize this to JSON
public List<Race>? Races { get; set; }
[JsonIgnore] // 👇 Do not serialize this to JSON
public List<RaceResult>? RaceResults { get; set; }
}
// 🏎️ Races
[Index(nameof(Date))]
public class Race {
[DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int Id { get; set; }
public required string Name { get; set; }
public required DateTime Date { get; set; }
public required decimal DistanceKm { get; set; }
[JsonIgnore] // 👇 Do not serialize this to JSON
public List<Runner>? Runners { get; set; }
[JsonIgnore] // 👇 Do not serialize this to JSON
public List<RaceResult>? RaceResults { get; set; }
}
// 🥇 Results (maps many-to-many)
// This is an implicit table that we don't access directly but
// through the navigation of the properties
[PrimaryKey(nameof(RunnerId), nameof(RaceId))]
[Index(nameof(BibNumber))]
public class RaceResult {
public int RunnerId { get; set; }
public int RaceId { get; set; }
public Runner Runner { get; set; } = null!;
public Race Race { get; set; } = null!;
public int BibNumber { get; set; }
public int Position { get; set; }
public TimeSpan Time { get; set; }
}Of note is that the actual client types for Prisma are generated via the command npx prisma generate while the Entity Framework model is simply the same as your data model. The latter is known as a "code first" approach which lets developers build a natural model and simply annotate how it should be mapped to the database layer for persistence.
Data annotations for mapping and data quality
Here, we see some basic data annotations to specify indices and primary keys. EF Core data annotations allow customization of the schema mapping. If you prefer more explicitness, you can also use fluent configuration instead. Combine these with .NET web API data annotations, .NET offers a painless way to handle most common data validation use cases.
Writing Data
Adding a Single Record
await tx.race.create({
data: {
name: 'New York City Marathon',
date: new Date(),
distanceKm: 42.195,
}
})db.Races.Add(new () {
Name = "New York City Marathon",
Date = new DateTime(),
DistanceKm = 42.195m
});
await db.SaveChangesAsync();A keen eye might notice that the Add() is not async in Entity Framework while it is awaited in Prisma. In Entity Framework, model mutations are tracked and not written to the database until an explicit call to SaveChangesAsync() which produces one transaction with all tracked model mutations. On the other hand, Prisma performs a direct mutation on the database on each call to create() or update() and multiple updates across related entities requires manual transaction management. In .NET with EF, the running code can continue to modify the model and add records and flush the changes in one atomic transaction.
This can be very useful when constructing large object graphs.
Adding Complex Relations
Here, we create a runner, a race, and a result for the runner and race.
const runner = await tx.runner.create({
data: {
name: 'Ada Lovelace',
email: 'ada@example.org',
country: 'United Kingdom',
}
})
const race = await tx.race.create({
data: {
name: 'New York City Marathon',
date: new Date(),
distanceKm: 42.195,
}
})
await tx.raceResult.create({
data: {
runnerId: runner.id,
raceId: race.id,
position: 1,
bibNumber: 1,
time: 120,
}
})var runner = new Runner() {
Name = "Ada Lovelace",
Email = "ada@example.org",
Country = "United Kingdom"
};
var race = new Race() {
Name = "New York City Marathon",
Date = new DateTime(),
DistanceKm = 42.195m
};
runner.Races = [race];
var result = new RaceResult() {
Runner = runner,
Race = race,
BibNumber = 1,
Position = 1,
Time = TimeSpan.FromMinutes(120)
};
runner.RaceResults = [result];
db.Add(runner);
await db.SaveChangesAsync();An important observation here is how the two queries behave. On the Prisma side, the entities are actually created and returned from the database with actual IDs that we then use in later queries to wire everything up. On the .NET side, we're simply dealing with an object graph and relying on Entity Framework to persist the entire graph in a single transaction on the call to SaveChangesAsync.
Reading Data
Here, we'll see how .NET's Language Integrated Query (LINQ) libraries make querying databases feel fluid through the use of a fluent, functional DX.
Basic Reads
// Composing where clauses
const loadedRunners = await tx.runner.findMany({
where: {
AND: [
{ name: { startsWith: 'Ada' } },
{ name: 'Alan Turing' }
]
}
}) // ✅ 0 results
// ℹ️ Skip the middle example because it's not
// relevant here for Prisma because JavaScript
// doesn't have expression trees.
// 2 results
const loadedRunners2 = await tx.runner.findMany({
where: {
OR: [
{ name: { startsWith: 'Ada' } },
{ name: 'Alan Turing' }
]
}
}) // ✅ 2 results// Composing Where clauses
var loadedRunners = await db.Runners
.Where(r => r.Name.StartsWith("Ada"))
.Where(r => r.Name == "Alan Turing") // logical And
.ToListAsync();
// ✅ 0 results
// Here we see .NET Expressions in action because
// we can actually read this equality expression at runtime
// and break it down. Cool! 😎
// Still 0 results; same query:
loadedRunners = await db.Runners
.Where(r => r.Name.StartsWith("Ada")
&& r.Name.StartsWith("Alan")
)
.ToListAsync();
// ✅ 0 results
// 2 results
loadedRunners = await db.Runners
.Where(r => r.Name.StartsWith("Ada")
|| r.Name.StartsWith("Alan")
)
.ToListAsync();
// ✅ 2 resultsThoughts on verbosity?
I've formatted the Prisma example to actually condense the code a bit. Overall, I find the Prisma query to be difficult to read and difficult to compose because it doesn't benefit from intellisense and autocomplete the same way that EF does.
.NET Expression trees
The logical expressions in the examples above should stand out because here, we've directly used the language level equality expression. Expression trees allow us to evaluate the expression at runtime to break apart its component structures to build the underlying SQL query (instead of using strings (Kysely) or manually constructing an expression tree (Prisma)).
Read with Navigation Includes
// Read the runners and include the navigation properties
const loadedRunners = await tx.runner.findMany({
include: {
races: {
include: { race: true }
}
}
})
// Read a specific runner with filtering
const loadedAda = await tx.runner.findFirst({
where: { email: 'ada@example.org' },
include: {
races: {
include: { race: true }
}
}
})// Read the runners and include the navigation properties
var loadedRunners = await db.Runners
.Include(r => r.RaceResults)
.Include(r => r.Races)
.ToListAsync();
// Read a specific runner with filtering
var loadedAda = await db.Runners
.Include(r => r.RaceResults)
.Include(r => r.Races)
.FirstAsync(r => r.Email == "ada@example.org");Complex Reads
// Read with a filter on the navigation for races where
// the runner finished in the top 10, 2 hours or less, and
// the race name contained the word "New"
const loadedAda2 = await tx.runner.findFirst({
where: { email: 'ada@example.org' },
include: {
races: {
where: {
AND: [
{ position: { lte: 10 } },
{ time: { lte: 120 } },
{
race: {
name: { contains: 'New' }
}
}
]
}
}
}
})
// ✅ Only Ada (Runner + RaceResult populated)
// Same read, but we only want the runners (not their results)
const loadedRunners2 = await tx.runner.findMany({
where: {
races: {
some: {
AND: [
{ position: { lte: 10 } },
{ time: { lte: 120 } },
{
race: {
name: { contains: 'New' }
}
}
]
}
}
},
})
// ✅ Only Ada (Runner only)// Read with a filter on the navigation for races where
// the runner finished in the top 10, 2 hours or less, and
// the race name contained the word "New"
var loadedAda = await db.Runners
.Include(r => r.RaceResults.Where(
finish => finish.Position <= 10
&& finish.Time <= TimeSpan.FromHours(2)
&& finish.Race.Name.Contains("New")
)
)
.FirstAsync(r => r.Email == "ada@example.org");
// ✅ Only Ada (Runner + RaceResult populated)
// Same read, but we only want the runners (not their results)
var loadedRunners = await db.Runners
.Where(r => r.RaceResults.Where(
finish => finish.Position <= 10
&& finish.Time <= TimeSpan.FromHours(2)
&& finish.Race.Name.Contains("New")
).Any()
).ToListAsync();
// ✅ Only Ada (Runner only)I've taken some liberal formatting here to help make the Prisma query more readable (Prettier would make this code even more lines!), but you can see that as the query gets larger, it is actually quite difficult to manage and refactor while the EF query remains quite legible and easy to understand. .NET has first-class expression trees that can be evaluated at runtime to produce the queries whereas on the Prisma side, the code is effectively building and expression tree.
With Prisma, a better strategy might be to use Prisma on the write side and Kysely on the read side much like how some teams with C# might use Entity Framework on the write side and Dapper on the read side for more complex queries (though Entity Framework's threshold for complex read queries is higher than Prisma's).
Prisma queries quickly become hard to manage and refactor as the number of conditions increase.
Refactoring pains...
Because Prisma entities are generated from the schema, refactoring can be a bit more...tedious. With Entity Framework, we can easily change the model in code and have the full support of the IDE to refactor our entity references. The migration will adjust schema changes automatically; effectively, Entity Framework always operates against the code model and therefore generally provides a better DX and superior productivity.
With Prisma, this is a much more tedious task because the entity model is an artifact of the schema!
Projection
// Load Ada's top 10 races, order by finish position, and
// project the results
const loadedAdasTop10Races = await tx.raceResult.findMany({
select:{
runner: { select: { name: true } },
race: { select: { name: true } },
position: true,
time: true
},
where: {
runner: { email: 'ada@example.org' },
position: { lte: 10 }
},
orderBy: { position: 'asc' }
})
// ⚠️ Note the difference in the format; it's not truly flattened
/**
* [
* { runner: { name: 'Ada Lovelace' }, race: { name: 'New York City Marathon' }, position: 1, time: 120 },
* { runner: { name: 'Ada Lovelace' }, race: { name: 'Boston Marathon' }, position: 5, time: 145 }
* ]
*/// Load Ada's top 10 races, order by finish position, and
// project the results
var loadedAdasTop10Races = await db.Runners
.Where(r => r.Email == "ada@example.org")
.SelectMany(r => r.RaceResults!.Where(
finish => finish.Position <= 10)
)
// ✨ Notice how everything is fully typed downstack
.Select(finish => new {
Runner = finish.Runner.Name,
Race = finish.Race.Name,
finish.Position,
finish.Time
})
.OrderBy(r => r.Position)
.ToListAsync();
/*
* [
* { Runner: "Ada Lovelace", Race: "New York City Marathon", Position: 1, Time: 00:02:00 }
* { Runner: "Ada Lovelace", Race: "Boston Marathon", Position: 5, Time: 00:02:25 }
* ]
*/It's important to make a note of the output shape from the query. Note that on the Entity Framework side, the results are actually projected into a flat model that doesn't have an entity mapping in our domain (we'll see later how to handle this). The .Select(finish => { ... }) expression translates into a SELECT projection with aliases that actually executes in the database and the return result is already flattened.
Anonymous types in action
The result of the select from the .NET side is an anonymous type. For transmitting, it probably makes sense to convert this into a Record.
Writing a Repository
Let's examine how we create repositories and connect them to our DI to make them available to controllers and services.
These implementations are not complete
See the unit tests in the repo for full implementations. The purpose of the API implementations is purely to demonstrate how the DI works and how things get wired up.
// 📄 results-repository.ts: Sample repository
@Injectable()
export class ResultsRepository {
constructor(
private readonly prismaService: PrismaService
) {
}
async top10FinishesByRunner(email: string) : Promise<RunnerRaceResult[]> {
return (await this.prismaService.raceResult.findMany({
select:{
runner: { select: { name: true } },
race: { select: { name: true, date: true } },
position: true,
time: true
},
where: {
runner: { email: 'ada@example.org' },
position: { lte: 10 }
},
orderBy: { position: 'asc' }
})).map(r => ({
runnerName: r.runner.name,
raceName: r.race.name,
position: r.position,
time: r.time,
raceDate: r.race.date
}))
}
}
export type RunnerRaceResult = {
runnerName: string,
raceName: string,
position: number,
time: number,
raceDate: Date
}
// 📄 app.module.ts: Register DI
@Module({
imports: [],
controllers: [AppController],
providers: [AppService, PrismaService, ResultsRepository],
})
export class AppModule {}
// 📄 app.controller.ts: Add our endpoint and DI
@Controller()
export class AppController {
constructor(
private readonly appService: AppService,
private readonly resultsRepository: ResultsRepository
) {}
@Get('/top10/:email')
async getTop10FinishesByRunner(
@Param('email') email: string
): Promise<RunnerRaceResult[]> {
return await this.resultsRepository.top10FinishesByRunner(email)
}
}// 📄 ResultsRepository.cs: Sample repository
public class ResultsRepository(
Database db // 👈 Injected via DI
) {
public async Task<
IEnumerable<RunnerRaceResult>
> Top10FinishesByRunner(string email)
=> (await db.Runners
.Where(r => r.Email == email)
.SelectMany(r => r.RaceResults!.Where(
finish => finish.Position <= 10)
)
.Select(finish => new {
RunnerName = finish.Runner.Name,
RaceName = finish.Race.Name,
finish.Position,
finish.Time,
RaceDate = finish.Race.Date
}
)
.OrderBy(r => r.Position)
.ToListAsync())
.Select(r => new RunnerRaceResult(
r.RunnerName,
r.RaceName,
r.Position,
r.Time,
r.RaceDate
));
}
public record RunnerRaceResult(
string RunnerName,
string RaceName,
int Position,
TimeSpan Time,
DateTime RaceDate
);
// 📄 Program.cs: set up our DI
builder.Services.AddScoped<ResultsRepository>();
builder.Services.AddSingleton(new DbConfig(connectionString));
builder.Services.AddDbContext<Database>();
// 📄 AppController.cs: Add our endpoint and DI
[ApiController]
[Route("[controller]")]
public class AppController(
ILogger<AppController> logger,
ResultsRepository resultsRepository // 👈 Injected here
) : ControllerBase {
[HttpGet]
public string Get() => "Hello, World!";
[HttpGet("/top10/{email}")]
public async Task<
List<RunnerRaceResult>
> GetTop10FinishesByRunner(string email) {
return [.. await resultsRepository.Top10FinishesByRunner(email)];
}
}An important distinction
On the TypeScript side, the .map projection takes place on the client side after the result has been returned. On the .NET side, the projection and aliasing takes place on the database server; the first .Select() expression is transformed into a SQL SELECT field AS alias, ... whereas the second Select() materializes it into the record.
Hoisting Navigations
EF Core will attempt to persist the entire object tree if you round-trip the entity. To prevent this -- for example, we only want to round-trip the runner -- we can use a simple technique here to split out the navigation collections from the results:
// 📄 results-repository.ts: Retrieve a runner and her results
async runnerResults(email: string) { // Only a shape here, not a type
return await this.prismaService.runner.findFirst({
where: {
email: 'ada@example.org'
},
include: {
races: { // 👈 Included
include: { race: true } // 👈 Included
}
}
})
}
// We "hoist" our dependent properties here.
type RunnerResults = {
runner: Runner,
results: RaceResult[], // 👈 We'll hoist includes here
races: Race[] // 👈 We'll hoist includes here
}
// 📄 app.controller.cs: Endpoint for runner and results
@Get('/results/:email')
async getRunnerResult (
@Param('email') email: string
) : Promise<RunnerResults> {
const result = await this.resultsRepository.runnerResults(email)
return {
runner: result, // Requires manual trimming
results: result.races, // Requires manual trimming
races: result.races.flatMap(r => r.race) // Requires manual trimming
}
}// 📄 ResultsRepository.cs: Retrieve a runner and her results
public async Task<Runner> RunnerResults(string email)
=> await db.Runners
.Include(r => r.RaceResults) // 👈 Included
.Include(r => r.Races) // 👈 Included
.FirstAsync(r => r.Email == email);
// We "hoist" our dependent properties here.
public record RunnerResults(
Runner Runner,
Races[] Races, // 👈 We'll hoist includes here
RaceResult[] Results // 👈 We'll hoist includes here
);
// 📄 AppController.cs: Endpoint for runner and results
[HttpGet("/results/{email}")]
public async Task<RunnerResults> GetRunnerResults(string email) {
var result = await resultsRepository.RunnerResults(email);
return new(
result, // 👈 Will NOT have .Races and .RaceResults in JSON output
[..result.RaceResults ?? []], // 👈 Hoisted
[..result.Races ?? []] // 👈 Hoisted
);
}Remember how we used [JsonIgnore] in our model? This means that at serialization at the boundary, Runner.Races and Runner.RaceResults will automatically be stripped out (nice)! So to keep them in the output JSON, we need to "hoist" them up into a "DTO" record.
On the Prisma side, it's not so easy. We'll either have to do a deeper selection or explicitly delete fields off of our objects to ensure they do not round trip. It's possible to use lodash's omit or JavaScript delete to remove the navigations manually.
TIP
This is an extremely useful pattern and should generally be used for all navigation properties as it will allow round-tripping the entity for updates without passing the navigations along.
Adding Migrations
# From /src/typescript/prisma-api
npx prisma migrate dev --name init
# https://github.com/prisma/prisma/discussions/24875#discussioncomment-10774638
# Generate idempotent SQL file (best for upstream deployment)
npx prisma migrate diff \
--from-empty \
--to-schema-datamodel ./prisma/schema.prisma \
--script > ./prisma/migrations/000000000000_init/migration.sql# From /src/csharp/ef-api
dotnet ef migrations add Initial
# Generate idempotent SQL file (best for upstream deployment)
dotnet ef migrations script \
--output Migrations/Scripted/migration.sql \
--idempotent
# Apply updates
dotnet ef database updatePerformance
I've captured results here using the Fortunes benchmark from TechEmpower from Round 23 (2025-02-04). The description of the Fortunes benchmark is as follows:
Exercises the ORM, database connectivity, dynamic-size collections, sorting, server-side templates, XSS countermeasures, and character encoding.
The results have been filtered down to "full" ORM stacks to bypass partial ORMs (like Dapper) and raw data access. The last two columns indicates that these results are "full ORM" and "realistic approach" for the platform.
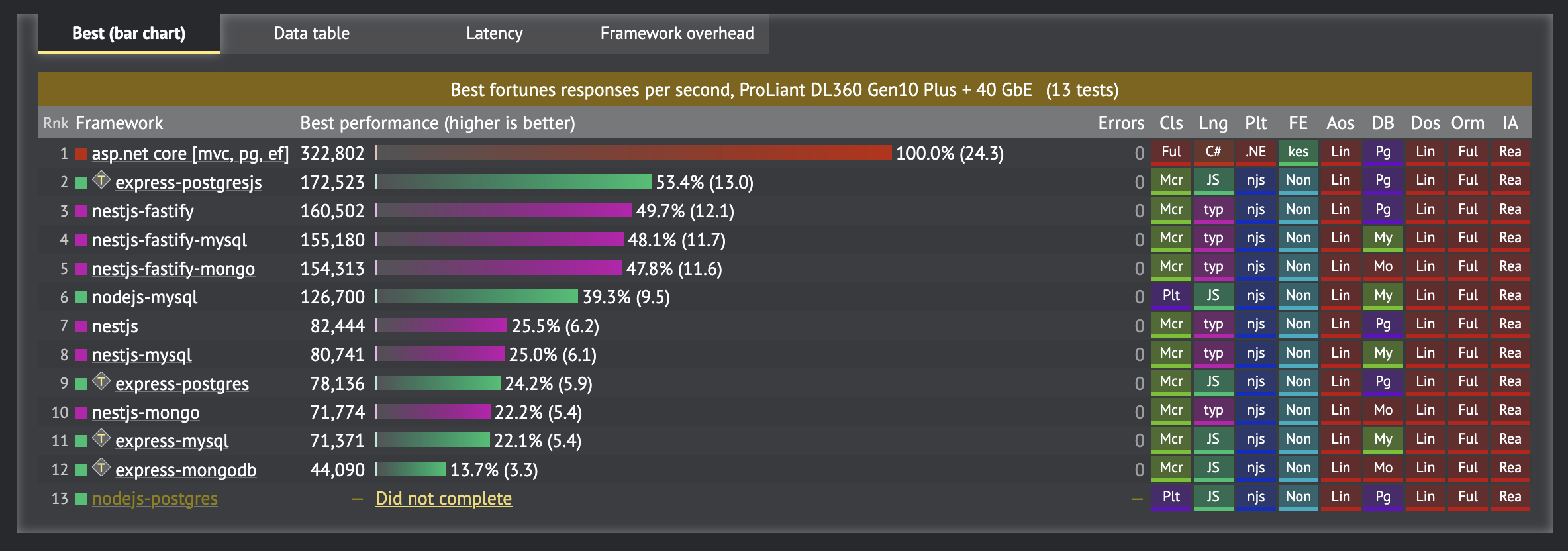
Think of these results as "throughput"
I think the practical way of thinking of these results as the volume of throughput for a given dollar amount in hardware spend; it's not about shaving 3ms off of the response time, it's responding to more clients using the same amount of infrastructure.
In other words, "You'll spend up to 4x as much on application infrastructure with Nest.js to support the same volume of requests."
Note on the Node.js ORMs
For Nest.js, the ORM used is TypeORM (see source). For Node.js, it's Sequelize (see source). For Express, it is also Sequelize (see source).
Prisma is generally known to be lower throughput, but is the most popular framework on Node.js